Mining social media
Testing different packages and tools to mine Twitter and Instagram.
Purpose
This evaluation was carried out as a researcher request to test methods for extracting data from the social media accounts of The United Nations [Twitter (UN) and Instagram (unitednations)].
Social media data typically describes information created and curated by individual users and collected using public platforms. 1 As social media platforms have increasingly become an integral part of everyday life, data gathered from these services have become more and more interesting for academic researchers.
Researcher Goal
[05/05/2020] - “For both twitter and Instagram, I only want the main UN account: @UN (twitter) and unitednations (Insta). Is it possible to get tweets from all of 2019?”
Limitations & Constraints
Scraping Social Media data
Traditional social media scrapers either use a browser to access data from a web page, or they extract it manually through an API endpoint (Application Programming Interface). Web APIs are generally used to deliver data in a form that computers can understand and use.
A number of tools were used in this evaluation as each has their own strengths and weaknesses. The Twitter code using using the Twitter API and an approved access token. The Instagram code and software crawls public Instagram data via the author’s Profile without the need to have access to the official API.
Access conditions
Not all APIs work the same way and each has certain limitations as how they are implemented.
The standard (free) Twitter API limits general searches by setting limits on the total number of tweets that can be captured and only allowing you to collect tweets going over the past 10 days.Neither of the standard API mechanisms support working with historical tweets.
Using the Instagram API requires an access token. Access requests must go through a App Review process that specifying ‘the type of data your app will be requesting from users and describing how you will use that data.’ 1
NB: The InstaCrawlR code tested extracts the metadata for a large number of Instagram posts that include a particular hash-tag. While this may have some further utility in carrying ut social network analysis (SNA), it is not useful for collecting data from a specific account.
Ethics
The datasets created are raw datasets that have not been anonymised or cleaned. Appropriate care should be taken displaying any personal user information contained without appropriate ethics approval.
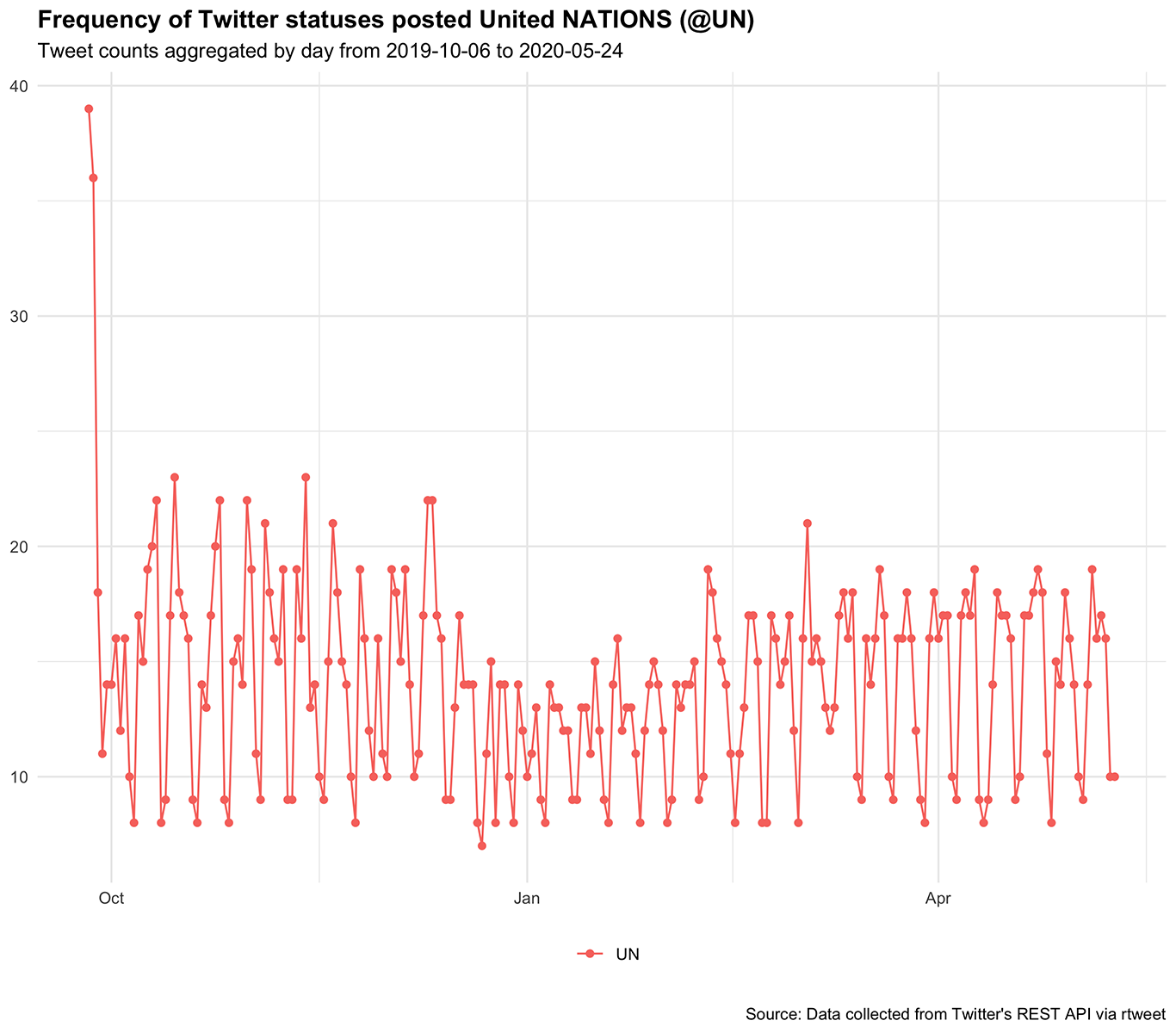
Results
Datasets summary
| Application | Dataset | Filename |
|---|---|---|
| rtweet | 3238 tweets | rtweet-UN-2985.csv |
| tweepy | 3248 tweets | tweepy-UN-3248.csv |
| InstaCrawlR | 3287 posts | InstaCrawlR-UN-3287.csv |
| 4K Stogram (Instagram) | 5,236 photos/videos | unitednations.zip (3.17GB on disk) |
| TAGS (Twitter) | 2985 tweets | TAGS-Archive-UN-2985.csv |
Download datasets
Datasets for analysis can be downloaded from Cloudstorr
Software used
rtweetreference docs: https://docs.ropensci.org/rtweet/index.htmltweepyreference docs: http://docs.tweepy.org/en/latest/TAGSurl: https://tags.hawksey.info/
InstaCrawlRreference docs: https://github.com/JonasSchroeder/InstaCrawlR / reference docs: https://towardsdatascience.com/build-your-own-instagram-database-134281e8ee924K Stogramurl: https://www.4kdownload.com/products/product-stogram